Demystifying AI Terminology
James Smith · Co-founder & CEO
15 August 2024

Artificial Intelligence (AI) is a fascinating and rapidly evolving field of computer science with many specialised subfields and terms. For those new to the topic, understanding these terms can be overwhelming. This blog post aims to demystify some key AI terminology: Generative AI (Gen AI), Machine Learning (ML), AI itself, and related concepts like Large Language Models (LLMs), Frontier Models, Foundation Models, and more. It’s useful to understand these before discussing important issues like data licensing.
Artificial Intelligence (AI): A Branch of Computer Science
Let's start with the big picture. AI is a broad field within Computer Science that aims to give computer systems capabilities typically associated with human intelligence. These capabilities include reasoning, learning, problem-solving, perception, language understanding, decision-making, creativity, and interaction with humans and the world. AI encompasses various techniques and technologies designed to make machines smarter and more autonomous.
The capabilities of AI systems have evolved over time. Early AI systems had limited computing power and training data, so they relied on predefined rules configured by programmers to simulate a narrow set of human abilities. Famous examples include ELIZA, a 1960s chatbot that used pattern matching and conversation scripts to give the illusion of understanding in textual chat, and Deep Blue, a chess supercomputer that used purpose-built algorithms and brute-force computing power to defeat world champion Garry Kasparov in 1997.
While these early systems performed well in certain situations, they had limited scope and had to be explicitly programmed to handle new situations.
Modern AI systems take advantage of two recent changes to expand their capabilities: 1. the huge leap in computing power provided by specialised AI accelerators, and 2. the explosion of training data, enabled by the internet and the proliferation of digital content.
This has enabled the creation of AI assistants like OpenAI's ChatGPT, biological analysis tools like DeepMind's AlphaFold, image generators like Stability AI's open source Stable Diffusion, and autonomous driving systems like Alphabet's Waymo.
Consider AI as an "umbrella" term, beneath which we find more specific concepts like Machine Learning (ML) and Generative AI (Gen AI).
Machine Learning (ML): The Engine of AI
ML is a subset of AI that involves developing algorithms and statistical models enabling computers to learn from data and make predictions or decisions. Unlike traditional programming, where explicit instructions are given for each task, ML models improve their performance as they are exposed to more high-quality data over time.
Techniques in ML include supervised learning, unsupervised learning, reinforcement learning, and deep learning.
Gen AI: The Creative Side of AI
Generative AI (Gen AI) is a specialised area within AI and ML that involves creating models capable of generating new content. This content can range from text, images, audio, and videos to synthetic data.
Diffusion models (e.g Stable Diffusion) and Transformers (e.g. ChatGPT) are examples of Gen AI models, designed to produce realistic and creative outputs based on their training data.
Distinguishing between AI, ML, and Gen AI
AI is the overarching field focused on making intelligent machines.
ML is a subset of AI that uses data to teach machines to learn and make decisions.
Gen AI is a specialised application of AI and ML focused on generating new, synthetic content.
Understanding LLMs, Frontier Models, and Foundation Models
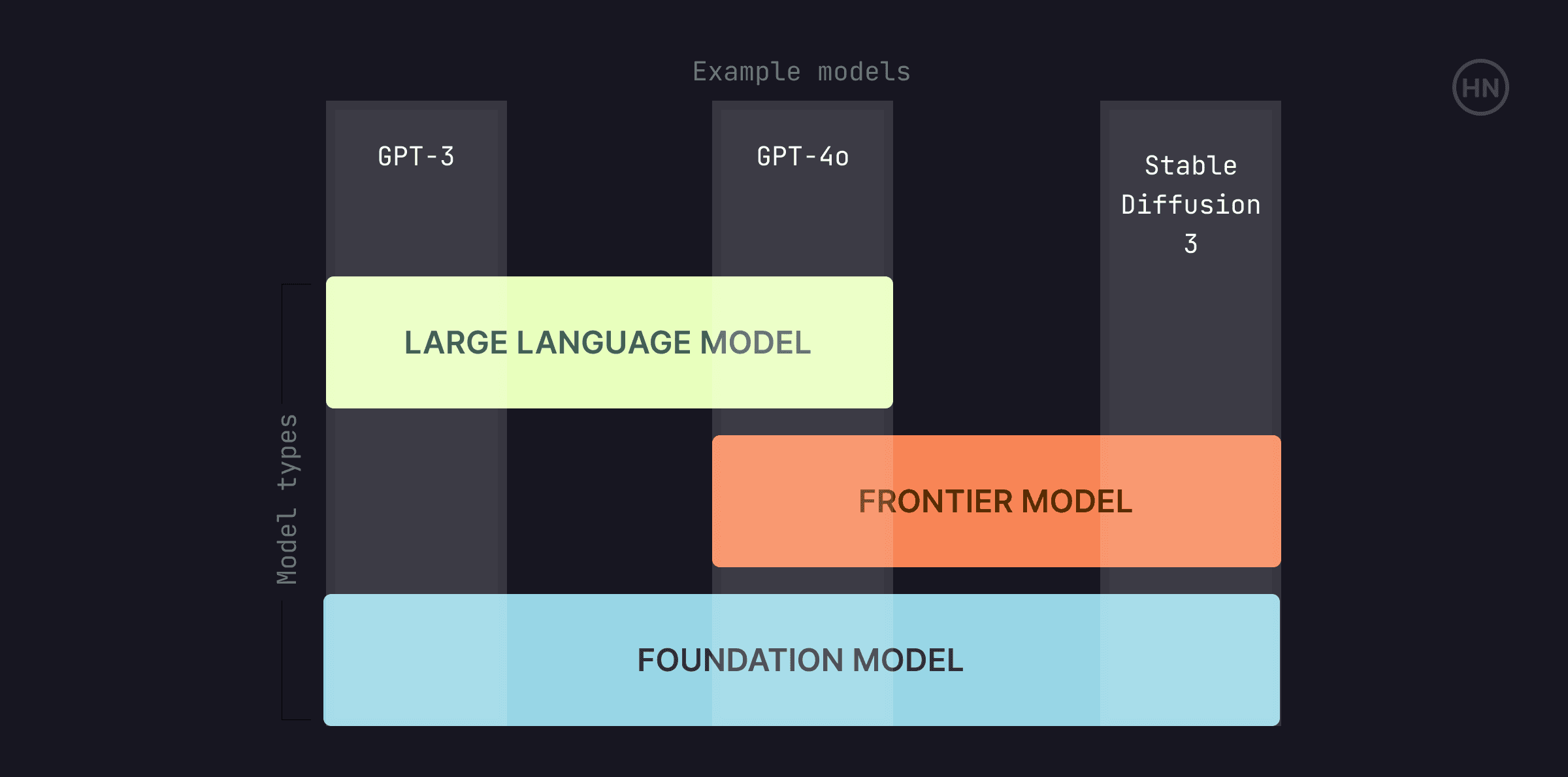
LLMs (Large Language Models)
LLMs are AI models designed to understand and generate human language. Trained on vast amounts of text data, these models utilise deep learning techniques to perform tasks like text generation, translation, summarization, and question answering. Examples include models like GPT-4o, Mistral Large, and Claude 3.5 sonnet.
Frontier Models
Frontier Models represent the cutting edge of AI research and development. These models push the boundaries of what is currently possible in AI, incorporating the latest advancements in technology and methodologies. They often include the most advanced iterations of LLMs and other novel AI systems.
Foundation Models
Foundation Models are large-scale AI models that serve as a basis for a wide range of downstream tasks. They're pre-trained on broad datasets and can be fine-tuned for specific applications, providing a versatile starting point for many AI systems. Examples include BERT and GPT-4o, which are used as starting points for many AI applications.
Distinguishing between LLMs, Frontier Models, and Foundation Models
LLMs are specialised in language tasks and built on large text datasets.
Frontier Models are the most advanced AI models, representing the latest breakthroughs.
Foundation Models are versatile models pre-trained on extensive data, adaptable for various specialised applications.
So yes, it is possible for a model to be an LLM, a frontier model, and a foundational model! GPT-4o would be such an example.
The Data Behind AI
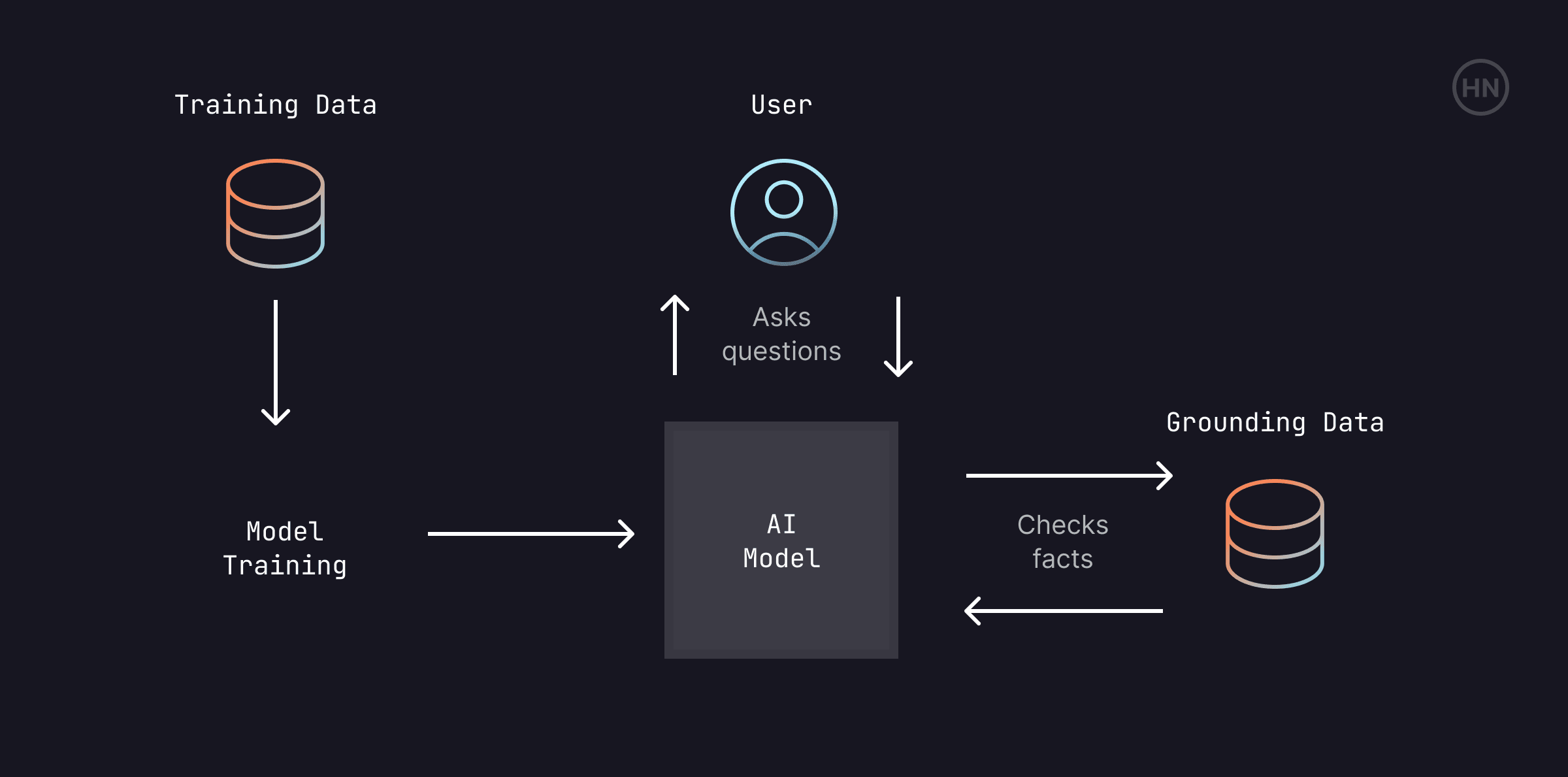
AI models are only as good as the data they're trained on. The phrase "Garbage In, Garbage Out" is very applicable for all kinds of AI models.
Training Data
Training Data is the dataset used to initially train an AI model. It's the foundation of the model's knowledge and capabilities. Training data is usually a large amount of data, from which the model can learn patterns and relationships to predict the output. The quality, size, and diversity of training data significantly impact a model's performance.
Examples of large, commonly used training data sets are FineWeb and CommonCrawl.
Grounding Data
Grounding Data provides specific, often up-to-date, information to give an AI model context or "ground" its responses in current or specific facts. This data serves as a reference point to validate and adjust the model's predictions based on real-world knowledge or specific contexts.
Examples of grounding data sets might be any AI system that is augmented with up-to-date content from a reputable source.
Distinguishing between Training Data and Grounding Data
Training Data is used to teach the model during its initial learning phase.
Grounding Data ensures the accuracy and relevance of the model's outputs.
Distinguishing between Training and Inference
Training is the initial phase of AI development, where an AI model learns to perform a task by being exposed to data.
Inference is the stage after training, where an AI model processes new data (Grounding Data) to generate predictions based on its existing knowledge.
Additional Key Concepts
Tokens
In the context of AI, particularly in natural language processing (NLP) and models like GPT, tokens are the fundamental units of text that the model processes and generates.
In simple terms, words and tokens are related but not always the same.
Words are the complete words as we typically understand them in language, like "cat," "running," or "hello."
Tokens are the pieces of text that an AI model processes, and they can be words, parts of words, or even single characters.
For example:
The word "running" might be one word, but it could be split into two tokens, "run" and "ning."
The sentence "I love AI." might be split into four tokens: "I," "love," "AI," and the period ".".
So, while tokens can be words, they can also be smaller parts of words or other elements like punctuation.
In general, if you are a rights holder thinking about the size of your corpus in "tokens" it is helpful to just think about the total word count.
Crawling vs. Scraping
Crawling: Systematically browsing and indexing web pages to collect data for further processing.
Scraping: Extracting specific data from web pages, focusing on targeted information.
RAG (Retrieval Augmented Generation)
Retrieval Augmented Generation (RAG) is a technique that combines a pre-trained language model with the ability to retrieve and use specific information from an external knowledge base. RAG enhances generative models by incorporating retrieved information, ensuring more accurate and contextually relevant outputs. This is a common way that grounding data is accessed by an AI model.
Pattern Matching
Pattern matching is a technique used to find specific sequences or patterns within a larger dataset. It is widely used in text processing, image recognition, and data analysis, involving techniques like exact matching, approximate matching, and using regular expressions.
Vectors in AI
In AI, a vector is a numerical representation of data. It's how machines "understand" complex information like words or images. Vectors enable AI models to perform tasks like classification, clustering, and similarity search.
Types of Data in AI Training
There are several types of data which may be useful to training AI systems:
Labelled Data: Annotated with labels for supervised learning.
Unlabelled Data: Raw data used in unsupervised learning.
Structured Data: Organised in tables (e.g., databases).
Unstructured Data: Without predefined structure (e.g., text, images).
Synthetic Data: Artificially generated to mimic real-world data.
Time-Series Data: Sequential data points over time.
Spatial Data: Includes geographical information.
Sensor Data: Collected from sensors (e.g., IoT applications).
Transactional Data: Generated from transactions (e.g., financial records).
Types of content useful for Generative AI training
Depending on the Generative AI model, different types of content are useful and in-demand for training and augmentation:
Text: news, books, scientific articles, social media. Usually measured in terms of number of words.
Images: photography, illustrations, artwork. Usually measured in the number of distinct images.
Video: film, television, documentaries, wildlife. Usually measured in hours of content.
Audio: music, conversational audio (i.e. podcasts). Usually measured in hours of content.
Code: repositories of computer programming code. Usually measured in lines of code.
Conclusion
As AI continues to evolve, so does its terminology. Understanding these concepts helps us grasp the capabilities and limitations of AI systems. Whether you're a tech enthusiast, a rights holder, or simply curious about AI, having a clear understanding of these terms will help you navigate this rapidly advancing field.
About us
Human Native AI is an AI data marketplace that fairly benefits both rights holders and AI developers. We equip AI developers with the high quality, wide-ranging data needed to train powerful AI systems like Large Language Models, while ensuring rights holders are fairly paid for use of their work.
If you are interested in participating in our data marketplace -> sign up now.